
Insbesondere Youtuber, aber auch Podcaster beschäftigen sich viel mit ihrem Mikrofonklang. Das macht auch Sinn, da gerade schlechter Sound die Zuschauer und -hörer vergraulen kann. Aus dem Grund ist eine der meist gestellten Fragen: Wie bearbeite ich meinen Sound eigentlich richtig nach? Aber kurz und knapp: Es gibt nicht den einen Weg und erst recht nicht den einen Sound. Dieser Bereich hängt von vielen Faktoren ab. Der Sound wird ausgemacht von der eigenen Stimme, dem Mikrofon und auch der Raumakustik. Entsprechend gibt es keine Universallösung. Nicht zuletzt ist der Wunschsound wieder sehr subjektiv. Jeder hat andere Vorlieben und empfindet andere Parameter als Wohlklingend.
Das Video wird von Youtube eingebettet abespielt.
Nichts desto trotz versuche ich hier eine kleine Einführung in die Nachbearbeitung zu geben und beschränke mich dabei erst einmal auf einen Equalizer und einen Kompressor. Dabei handelt es sich um zwei Hilfsmittel, die es in nahezu jedem Programm gibt, mit dem ihr euren Sound aufbessern könnt. Entsprechend wird diese Anleitung auch allgemeiner gehalten. Insgesamt ist das hier auch nicht als DIE Lösung zu verstehen sondern als kleiner Leitfaden, der euch auf dem Weg zu eurem Sound weiterhelfen soll.
Das richtige Programm
Die erste Frage, vor der viele stehen ist: Welches Programm soll ich denn nun nehmen? Wie schon angedeutet, ist das relativ egal, solange die entsprechenden Werkzeuge an Bord sind. Trotzdem gibt es Programme, mit denen die Arbeit wesentlich leichter oder schwerer von der Hand geht. Eine beliebte Empfehlung ist Audacity. Klar, das Programm ist kostenlos und nahezu unendlich Mächtig, was den Audiobereich angeht. An vielen Stellen fehlt aber der Komfort, ohne den der erste Weg zur eigenen Bearbeitung extrem erschwert wird. Ich würde aus dem Grund eine abgespeckte Version großer DAWs empfehlen, denn die bekommt ihr meist gratis zu einem Großteil der Audiohardware.
Ich selbst setze auf Sony bzw. jetzt Magix Moviestudio. Zu diesem Programm gibt es eine kostenlose Testversion eben so wie zum großen Bruder Magix Vegas 14. Das schöne an diesem Programm ist, dass der Workflow sehr dicht an dem gängiger DAWs liegt, es sich im wesentlichen aber um ein Videoschnittprogramm handelt. Somit kann die Video- und Audiobearbeitung Hand in Hand gehen. Trotzdem lässt sich natürlich alles hier beschriebene auf jedes andere Programm übertragen.
Die Theorie
Bevor es nun an die Praxis geht, gibt es wie so oft etwas Theorie vorab. Unser aufgenommener Ton hat üblicherweise eine Frequenzbreite von 22.050 Hz bis 24.000 Hz. Die Stimme findet sich auf einem großen Teil davon wieder. Wenn man nun einzelne Frequenzbereiche nimmt und anhebt oder absenkt, verändert man den Klang des aufgenommenen erheblich. Dazu habe ich eine kleine Grafik gebastelt, mit den wichtigsten Frequenzbereichen für die Stimmbearbeitung.
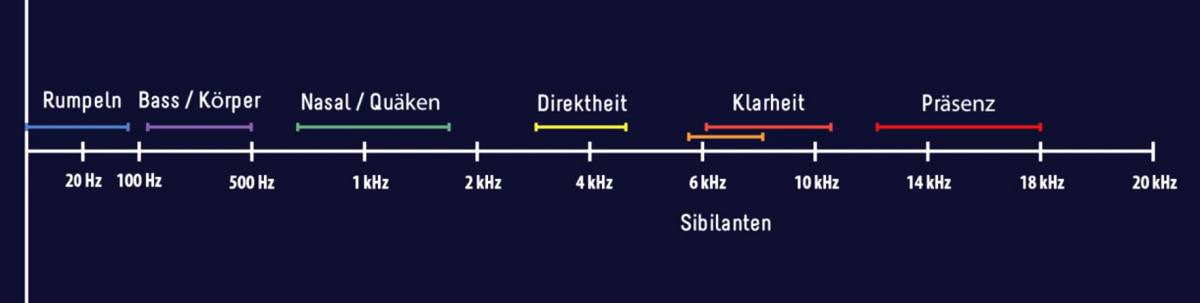
- <80 Hz: Hier befinden sich extrem tiefe Bässe. Im Alltag ist das meist dumpfes Rumpen, das durch Trittschall oder sonstigen Kontakt mit der Mikrofonhalterung oder dem Mikro direkt entsteht. Diesen Bereich kann man im Regelfall durch einen Lowcut-Filter bzw. ein allgemeines Absenken entfernen.
- 100 Hz – 500 Hz: Hier befindet sich der Bass und der Körper eurer Stimme. Der Bereich ist entscheidend dafür, wie voll eure Stimme klingt. Ihr solltet euch mit Bedacht an kleine Unterfrequenzbereiche wagen, da ihr so nicht nur mehr Volumen für eure Stimme bekommt, der Sound kann auch schnell muffig und dröhnend werden, wenn ihr es an der falschen Stelle übertreibt.
- 700 Hz – 1,8 kHz: In diesem Bereich findet ihr häufig das, was für den nasalen oder quäkenden Sound verantwortlich ist. Dagegen hilft meist ein leichtes Absenken der Problemzonen. Dadurch wirkt die Stimme meist bedeutend runder. Aber Vorsicht – auch hier gilt: Weniger ist mehr. Übertreibt ihr es, klingt es wie immer schnell unschön.
- 3 kHz – 5 kHz: Geht eure Stimme unter und wirkt kraftlos, könnt ihr mit leichten Anhebungen in diesem Bereich entgegenwirken.
- 6 kHz – 7,5 kHz: In diesem Bereich findet ihr die Sibilanten. Das sind die scharfen S-, Z-, P- und T-Laute. Wenn die durch eure Aufnahme schneiden, könnt ihr sie hiermit durch leichtes Absenken bändigen. Ist so ein scharfer Sound ein allgemeines Problem könnt ihr diesem mit einem DeEsser noch effizienter zu Leibe rücken, ohne den restlichen Sound negativ zu beeinflussen.
- > 6 kHz: Oberhalb der 6 kHz befindet sich zum einen die Klarheit, die insbesondere zur Durchsetzung in der Gesamtaufnahme, aber auch für die Sprachverständlichkeit wichtig ist. Darüber gibt es noch etwas mehr Präsenz für luftigeren Klang. Den Bereich kann man bei den meisten Mikros pauschal anheben. Aber Vorsicht, übertreibt ihr es, klingt eure Aufnahme zu harsch. Außerdem läuft man schnell Gefahr bei nicht sonderlich rauscharmen Mikrofonen das Rauschen mit zu verstärken. Also wieder mit Bedacht arbeiten!
Der Equalizer
Der Equalizer hilft uns nun die zuvor vorgestellten Frequenzbereiche anzuheben oder abzusenken. Dabei trefft ihr im wesentlichen auf zwei Arten von Equalizern. Zum einen den grafischen Equalizern. Bei diesen habt ihr eine Reihe von Reglern bei denen jeder für eine feste Frequenz bzw. einen festen Frequenzbereich steht, den ihr damit anheben oder absenken könnt. Diese Equalizer sind weniger flexibel, bringen euch je nach Anzahl der Frequenzbereiche aber auch mehr oder weniger komfortabel als Ziel.
Wesentlich mächtiger sind da die parametrischen Equalizer. Bei denen habt ihr die Möglichkeit die Frequenz, die Breite des betroffenen Bereichs und Stärke der Anhebung bzw. Absenkung festzulegen. Durch vorheriges testweises anheben schmaler Frequenzbereiche könnt ihr über den kompletten Frequenzbereich prüfen, ob euch besonders störende Frequenzen auffallen, die ihr auf jeden Fall bearbeiten müsst. Der Rest ist reines Ausprobieren mit dem Wissen über die Frequenzbereiche, das ihr oben sehen könnt.
Der Kompressor
Der Kompressor ist ein kleines Werkzeug, dass uns etwas Dynamik aus der Aufnahme nimmt. Man könnte jetzt meinen, das wäre schlecht, aber genau das Gegenteil ist der Fall. Die Dynamik bezieht sich auf den Bereich von lauten und leisen Signalen und verringert diesen Abstand. Insgesamt ist der Unterschied zwischen leisen und lauten Geräuschen im Anschluss geringer. Dies ist aus mehreren Gründen sinnvoll. Wenn ihr beispielsweise Let’s Plays oder zusammen mit Musik aufnehmt, habt ihr mit dem Ingame-Sound bzw. der Musik bereits eine weitere Tonspur, die im Regelfall stark komprimiert ist, um möglichst viel Druck auf die Ohren zu bekommen. Wenn ihr da nicht mitzieht, müsst ihr eure Stimme bedeutend lauter stellen, sonst geht sie gnadenlos dagegen unter.
Der andere Grund gilt mehr euren Zuhörern. Wenn ihr flüstert, müssen diese ihre Anlagen ganz schön aufdrehen. Sobald ihr danach jedoch schreit… fegt es denen die Löffel weg. Nach einer guten Kompression passiert das eben nicht mehr. Im wesentlichen behebt ihr damit das Problem, dass ihr vielleicht von Kinofilmen Zuhause kennt. Für die Dialoge müsst ihr den Fernseher aufdrehen, kommt aber eine Explosion, hat auch euer Nachbar etwas davon.
Wie funktioniert also nun unser Kompressor? Im Regelfall haben wir eine übersichtliche Parameteranzahl:
- Schwellenwert (Threshold): Dieser Wert gibt die Schranke an, ab welcher Lautstärker euer Signal komprimiert wird. Das hängt von eurer Signalstärke ab. Ich bevorzuge eine leichte Kompression, die nicht permanent greift. Da mein Pegel dabei meist zwischen -20 und -10 dB rumdümpelt, wähle ich also einen Wert zwischen -15 und -12 dB.
- Anstieg (Attack): Dieser Wert regelt, wie lange der Kompressor benötigt, bis euer Signal nach überschreiten der Schwelle komprimiert wird. Kurze Zeiten fangen plötzliche laute Signale ab, lange Zeiten machen die Absenkung sanfter. Meist ist hier aber ein kurzer Wert von 1-5 ms sinnvoll.
- Abklingzeit (Release): Dieser Wert ist quasi das Gegenstück zum Attack. Die Dauer, bis eure Kompression nach dem Absinken nachlässt. Hier ist ein verhältnismäßig hoher Wert von 300-500 ms sinnvoll. Ansonsten schnellt euer Signal nach der Kompression wieder in die Höhe, was zu unangenehmen Pumpen führen kann. Zudem werden so eigentlich leise Geräusche nach eurer Stimme betont. Konkret: Der Raumhall rückt merklich in den Vordergrund.
- Verhältnis (Ratio) x:1: Zu guter Letzt habt ihr das Kompressionsverhältnis. Das gibt einfach an, um welchen Faktor der Teil eures Signals, der über dem Threshold liegt, zusammengestaucht, also komprimiert wird. Für Sprache ist hier ein Verhältnis von 3:1 bis 5:1 sehr passend. Darüber hinaus wird es schnell unangenehm.
Viele Leute mögen für ihre Aufnahmen den typischen Radiomoderatorensound. Dafür wählt ihr ein stärkeres Kompressionsverhältnis und sorgt dafür, dass die Kompression schon bei geringeren Pegeln greift. Dadurch nähert ihr euch gut an. In der Praxis gibt es für diesen speziellen Bereich allerdings noch weitere Tools, die das besser bewerkstelligen können. Stichwort: Multiband-Kompressor. Auf solche erweiterten Möglichkeiten werde ich hier aber nicht eingehen.
Tipps zum Abschluss
Bevor ihr euch nun in wilde Bearbeitungen stürzt zwei wichtige Tipps. Zum einen solltet ihr euch, wenn ihr einen bestimmten Klang im Ohr habt, einfach mal eine Beispieldatei in euer Projekt holen. Beispielsweise von eurem Vorbild, was Sound angeht. Dann könnt ihr während der Nachbearbeitung immer zur Vorlage wechseln und nachhören, ob ihr euch schon erfolgreich angenähert habt. Zum anderen empfehle ich euch, bevor ihr eure Bearbeitung vollendet, das Ergebnis auf möglichst unterschiedlichen Systemen gegenzuhören. Beispielsweise über PC-Boxen, Laptop-Lautsprecher, Kopfhörer, Autoradio, Fernseher, … Denn nur weil es auf eurer jetzigen Abhöre gut klingt, heißt es nicht, dass die Einstellungen überall gut funktionieren.
Und mit diesen Hinweisen wünsche ich euch ein munteres Bearbeiten!